Document Parsing
Extract, process, and structure data from documents using intelligent parsing systems.
Document Extraction Overview
Document Parsing is the process of extracting meaningful and structured data from unstructured or semi-structured documents such as PDFs, images, and scanned files. By combining techniques like OCR and natural language processing, systems can interpret and organize information automatically.
Parsing Implementation
We build Document Parsing systems that automate data extraction from various document types, including invoices, forms, contracts, and reports. Our solutions identify key fields, classify document types, and extract relevant information with high accuracy using machine learning and AI techniques.
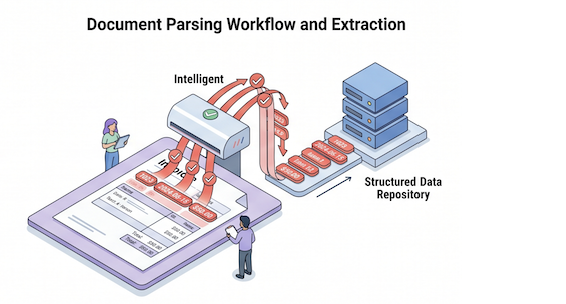
Validation & System Integration
Our solutions include built-in data validation, quality checks, and confidence scoring to ensure extracted data meets accuracy standards. We seamlessly integrate with your downstream systems, databases, and workflows, enabling real-time processing without manual intervention.
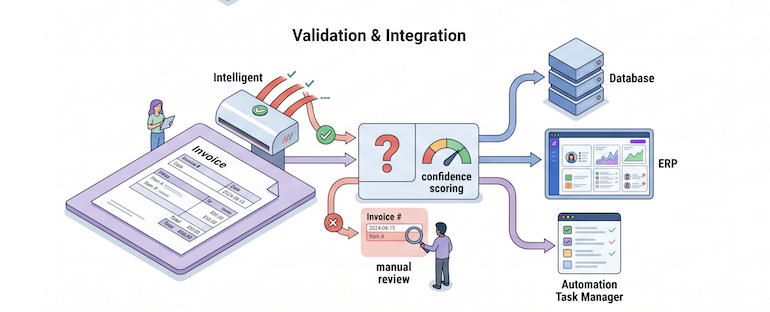
Accuracy & Automation Benefits
Our clients achieve faster processing, improved accuracy, and significant cost savings. Document Parsing reduces manual effort, minimizes errors, and enables real-time access to structured data, helping organizations streamline operations, improve compliance, and make better business decisions.
Ready to automate your
business operations?
Join 500+ global businesses scaling faster with our modular SaaS blocks. Get a personalized demo of your future dashboard today.